
Your GenAI models are live. The invoices don’t match the projections. You are not alone — and the fix is not cutting budgets. It is fixing architecture.
At Naveera Tech, we use a four-layer framework called the AI Cost Stack to control GenAI spend at the architecture level. Here is how it works.
The Real Cost of GenAI in Production — And Why Most Teams Get Blindsided
GenAI costs behave unlike anything else in your stack. Legacy budgeting models cannot keep up, and most teams lack the architectural controls to manage what they have built.
Why GenAI cost curves surprise engineering teams
Token pricing is non-linear. A basic Q&A call costs $0.002. Route that same question through a RAG pipeline with a 128K context window, and the cost jumps 50x. Inference also dwarfs training over time — 10x or more over a model’s production lifetime. Yet most budget conversations still focus on training.
The hidden cost multipliers — agentic loops, RAG pipeline overhead, and multi-model orchestration
RAG pipelines inject thousands of context tokens per call — paid whether the context helps or not. Multi-model orchestration stacks inference calls. Agentic loops trigger dozens of calls per user request. These are standard production patterns, not edge cases. Each one silently multiplies your baseline cost.
What the data says: AI spend growth in 2025–2026
- NVIDIA’s 2026 survey: 42% of enterprises named AI workflow optimization as their top spending priority.
- FinOps Foundation: 98% of practitioners now manage AI spend, up from 31% in 2024.
- Zylo: organizations spent $1.2M average on AI-native apps — a 108% YoY increase.
- Flexera: only 28% have mature cost practices despite 63% running AI in the cloud.
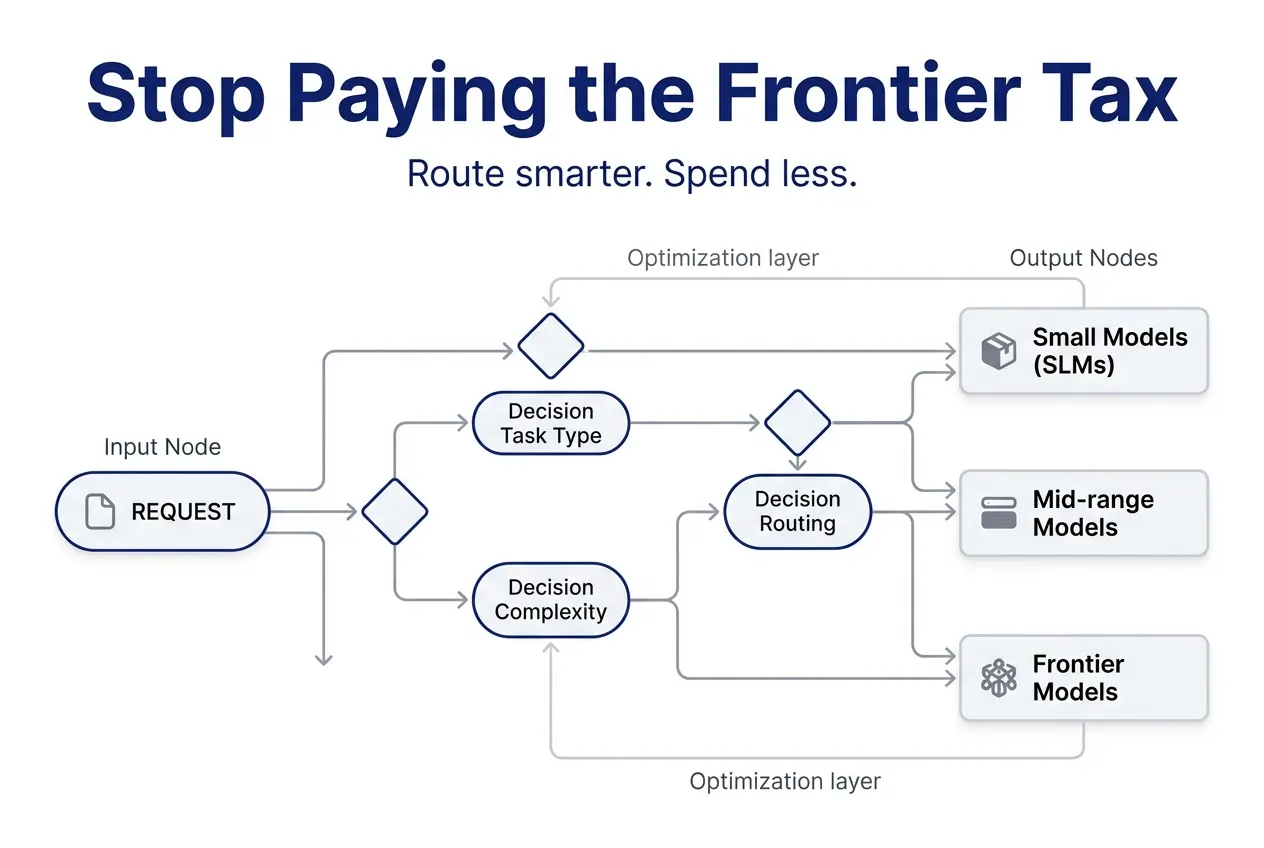
Model Selection and Intelligent Routing: Stop Using a Sledgehammer for Every Nail
The highest-impact cost lever in your stack. In our experience, 40–60% of production traffic runs on more expensive models than it needs.
The cost difference between frontier and task-specific models
A classification task a 3B-parameter model handles at $0.0001 per call often runs on a 400B-parameter model at $0.01. That is 100x more for identical output. The anti-pattern: teams pick one frontier model early and never revisit it.
How model routing works in production — tiered stacks and lightweight classifiers
A lightweight classifier sits in front of inference and routes each request to the right model. Three tiers: small (3B–8B) for extraction and classification, mid-range (30B–70B) for generation, and frontier for complex reasoning. Route by task type first, refine by measuring quality over time.
Model distillation — turning expensive teacher models into cheap, specialized students
Distillation trains a smaller student model using a larger teacher’s outputs. Azure AI Foundry offers this as a managed service. TensorZero benchmarks show 5–30x cheaper inference with competitive quality. If you run a high-volume workload on a frontier model, you likely have a distillation opportunity.
When to use SLMs vs. general LLMs — a decision framework
Two questions: Does the task require broad world knowledge and complex reasoning? Does quality degrade measurably with a smaller model? If both answers are no, you are paying a frontier tax for zero return. Classification, extraction, sentiment, and structured outputs all run well on 1B–7B parameter models.
Inference Optimization and Caching: Engineering the Cost Out of Every Token
Right model selected. Now make each call as cheap as possible.
Semantic caching — reusing responses based on meaning, not exact text match
Exact-match caching misses most natural language queries. Semantic caching converts queries into vector embeddings and compares meaning via cosine similarity. If similarity clears a threshold (start around 0.8), the cached response returns without hitting the model. On high-traffic workloads, this often pays for itself in the first billing cycle.
KV cache compression — reducing the 70% memory bottleneck in long-context inference
The KV cache during inference can consume up to 70% of GPU memory. ChunkKV (NeurIPS 2025) showed that compressing this cache using semantic chunks improved throughput by 26.5% without losing accuracy. For long-context workloads, this means more requests on existing hardware.
Quantization and parameter-efficient fine-tuning (LoRA) — doing more with less hardware
Quantization shrinks model weights to 8-bit or 4-bit precision — less memory, faster compute. LoRA freezes most parameters and trains only small adapter layers, cutting compute by 90–99% versus full fine-tuning. Best combination: distill, then LoRA fine-tune on your domain data.
Batching, scheduling, and spot instances — infrastructure-level cost levers
Batch non-urgent workloads for lower per-unit cost. Schedule GPU jobs during off-peak hours on spot instances. Right-size instances to actual requirements instead of defaulting to the largest available.
Taming Agentic Workflows: Budget Guardrails for Autonomous AI
The fastest-growing cost risk in production GenAI. Most teams are not prepared.
Why agentic workflows are cost landmines — token multiplication in multi-step chains
Each step in an agentic loop triggers inference calls. A $0.01 prompt-response becomes $0.15+ as a multi-step chain. At 500,000 daily requests, that is $75,000 per day for one workflow. Agents without stopping conditions loop indefinitely.
Budget guardrails — per-request token limits, per-agent cost ceilings, and kill switches
- Per-request token limits: Hard ceiling; return best answer when hit.
- Per-agent cost ceilings: Each agent gets its own budget; stops if exceeded.
- Kill switches: Maximum iteration count per loop (start with 5–10).
Design-time vs. run-time cost controls for agent orchestration
Design-time: Model mapping, context window limits, and tool-calling frequency caps. Run-time: Anomaly detection on token spikes and circuit breakers for non-converging loops. You need both.
Observability and cost tracing for multi-agent systems
Tag every inference call with trace ID, agent ID, and step number. You need per-step visibility: which step consumed the most tokens and which tool call triggered expensive retrieval. Same principle as distributed tracing for microservices.
FinOps for AI: Building the Governance Layer That Scales
Technical optimizations without governance erode silently.
What FinOps for AI looks like in 2026 — the shift from cloud-only to Cloud+
The FinOps Foundation changed its mission to “the value of technology.” 98% of practitioners now manage AI spend. AI is no longer a side concern — it is core FinOps territory.
The FOCUS specification — standardizing AI cost and usage data across vendors
FOCUS (FinOps Open Cost and Usage Specification) standardizes usage data. The upcoming 1.3 release adds split cost allocation for shared GPU clusters. FOCUS eliminates painful manual normalization across AWS, Azure, and GCP.
Shift-left cost architecture — embedding financial telemetry into CI/CD pipelines before deployment
Introduce cost awareness before provisioning. Include cost estimation in your deployment pipeline and cost-per-inference in your monitoring stack alongside latency and error rates. Cost becomes a first-class engineering signal.
Aligning engineering and finance teams on AI ROI metrics
The bridge: cost per inference, cost per solved task, and cost per business outcome. When both teams track the same numbers, optimization decisions happen faster.
Putting It Together — The AI Cost Stack and an Implementation Roadmap
The AI Cost Stack — a visual framework (Naveera original)
Four layers: Model Selection & Routing, Inference Optimization & Caching, Agentic Workflow Governance, and FinOps Integration. Work them in sequence by impact; govern them in parallel from Day 1.

Prioritization guide — where to start based on current maturity
- Layer 1: Audit model usage, implement routing (Biggest savings).
- Layer 2: Semantic caching on high-volume endpoints.
- Layer 3: Agentic guardrails before you scale.
- Layer 4: Tag and allocate costs from Day 1.
Metrics that matter — cost per inference, cost per solved task, token efficiency ratio, cache hit rate
Cost per solved task represents real unit economics. Token efficiency ratio tracks output tokens vs. total tokens. Target a 30–60% cache hit rate on repetitive workloads.
What a 90-day AI cost optimization engagement looks like (soft CTA)
- Weeks 1–3: Map workloads and establish baselines.
- Weeks 4–8: Implement routing, caching, and guardrails.
- Weeks 9–12: Measure impact and deploy governance dashboards.
FAQ
Q1: What is AI cost optimization in production, and why is it different from training cost optimization?
It targets inference — the ongoing cost of running models against live traffic. Inference scales with usage and routinely exceeds training costs over a model’s lifetime.
Q2: How much can semantic caching reduce LLM inference costs?
Yes. Services like Azure AI Foundry make it manageable, offering 5–30x cheaper inference with competitive quality for high-volume workloads.
Q3: Is model distillation practical for enterprise production workloads in 2026?
Yes. Services like Azure AI Foundry make it manageable, offering 5–30x cheaper inference with competitive quality for high-volume workloads.
Q4: How do agentic AI workflows create unexpected cost overruns?
Each step triggers inference calls. Loops and multi-step chains multiply tokens. Without budget guardrails, one misconfigured agent can exhaust API spend in hours.
Q5: What is FinOps for AI and how do we get started?
It is financial governance for AI. Start with cost visibility and tagging, add anomaly detection, then optimize through routing and right-sizing.